
TLDR; Accelerate large single file GCS transfers from 200 MiB/s for a single stream, to over 8 GiB/s with parallel streams
This guide will teach you how to parallelize your Google Cloud Storage (GCS) file transfers for dramatically increased throughput vs. single stream transfers. We’ll cover GCS API choices, optimized upload/download strategies, library and tool support, and best practices. Let’s get to it!
GCS API Support
Google Cloud Storage (GCS) offers a JSON API (Google’s own specification) and an XML API (compatible with AWS S3). Both are robust and suitable for demanding workloads, but there are subtle differences in their feature set. Usually the API used can be considered an implementation detail of your client libraries. If you’re using third party libraries or a utility with S3 support, just set the GCS service endpoint and potentially adapt some headers (x-amz-storage-class ⇨ x-goog-storage-class) and you’re good to go. Or if you’re developing something new with the Google Cloud Storage client libraries, the Firebase libraries, or using the gcloud storage CLI, usually the JSON API is leveraged.
I said usually twice above, and why I did that will become apparent in short order. 😀
Fast Uploads
Achieving fast uploads for large files requires these three steps:
- Logically split your file into byte-range chunks
- Upload the chunks in parallel
- Assemble the chunks to create the large file
Visually it looks like this:

To achieve this parallelization there are two techniques: Composite Uploads (JSON and XML API) and Multipart Uploads (XML API). While the basic concept of splitting and assembling is the same, the implementation differs. As a result, each technique has different limits and interoperability with other GCS features. Depending on your use case, both might do the job equally well, or one might be a better fit.
Lets walk through the flow of the Composite Upload pattern available with the JSON and XML API:

First, the file is logically split into byte ranges producing a number of chunks. Next, the chunks are uploaded in parallel as normal files to a temporary filename that is visible in the bucket. After all chunk files have been uploaded, a compose operation is issued that creates a new file from these chunks. Finally, the temporary chunk files can be deleted.
Now let’s walk through the flow of the Multipart Upload pattern available only with the XML API:

First, the file is logically split into byte ranges producing a number of chunks. Next, a Multipart Upload is initiated for the desired filename, and an uploadId is returned. Then, the chunks are uploaded in parallel as a partNumber of the uploadId into a hidden area of the bucket. After all chunks have been uploaded, a finalize operation creates a new file from the partNumber chunks, and also cleans up by deleting all chunk files associated with the uploadId.
Here are the differences when it comes to implementation and interoperability:
| Composite Uploads (JSON, XML) | Multipart Upload (XML) | |
| Treatment of chunk files | Normal files in the bucket | Special part files associated with an upload and stored in a hidden area of the bucket |
| Maximum number of chunks | 32, but the resulting file can itself be a chunk for a subsequent Compose operation iteratively without limit | 10,000 |
| Minimum chunk size | None | 5 MB for all chunks except the last one |
| Operations cost | Class A operations = (# chunks uploaded + 1 compose) | Class A operations = (# chunks uploaded + 1 create + 1 finalize). If you choose a very small chunk size the ops costs can add up! |
| IAM permissions required |
|
|
| Works well with bucket retention, holds, and soft delete | No. Applies to chunk and final files | Yes. Applies to final file only |
| Works well with colder storage classes | No. Minimum storage duration (and any early delete fees) is applicable for chunk files and final file. As an workaround, upload at STANDARD and update the storage class of the final file thereafter | Yes. Minimum storage duration (and any early delete fees) is applicable for final file only allowing upload at the desired colder storage class directly |
| Change notifications | Triggered for chunk files and final file | Triggered only for final file |
| Resumable upload support | Yes | No, but you can set the chunk size as low as 5 MiB to limit the amount of data that might need to be retransmitted |
| Automatic clean up of temporary chunks | No. Chunks must be deleted by client logic and/or by using an Object Lifecycle Manager (OLM) delete lifecycle action that removes older files that match a well-known prefix | Yes. A successful finalize or abort request deletes all chunks. Additionally, an Object Lifecycle Manager (OLM) AbortIncompleteMultipartUpload lifecycle action can be used to abort stale requests and delete their chunks |
| Likelihood to hit rate limits with technique | An object can be updated at most once per second. Ensure client logic, especially during repetitive composes, does not update the same object more frequently | No rate limits specific to Multipart Uploads |
| Google Cloud Storage client library support | All programming languages | transfer_manager module in the Node.js and Python libraries |
| gcloud storage utility support | Yes | No |
In summary, the Composite Upload pattern combines several distinct APIs to enable parallel uploads, whereas the Multipart Upload API is purpose built for it. As a result, Composite Uploads generally require more advanced client logic and don’t interoperate with GCS features including retention, holds, soft delete, and colder storage classes.
If Multipart Uploads are better in pretty much every way, why would you use Composite Uploads? The answer is simple: Client library and utility support.
But no fear, because Multipart Uploads are part of the XML API you can use client libraries or utilities that are S3 compatible, or use the transfer_manager module in the Node.js and Python Google Cloud Storage libraries. Calling the XML API directly for these uploads is also an option.
Fast Downloads
Achieving fast downloads for large files requires these three steps:
- Logically split your file into byte-range chunks
- Download the chunks in parallel
- Assemble the chunks to create the large file
Visually it looks like this:

Because your target is typically a file on a POSIX compatible filesystem, you can parallelize writes of different chunks directly to the relevant offsets in your local file. From an API perspective you are simply issuing range read GET requests against the large file on GCS. Both the JSON and XML APIs support range reads and can be used with comparable performance and feature interoperability.
Common GCS transfer tools / libraries
While there are many tools out there, the gcloud storage CLI and the Google Cloud Storage libraries remain the most common way to interact with GCS. Each has its own behaviors that you need to understand when designing for parallelism and peak performance. As a side note, I also tried s5cmd, rclone, and boto3, but was unable to match the performance possible with gcloud storage or the GCS Python libraries. Your mileage may vary.
gcloud storage
gcloud storage can parallelize uploads and downloads using multiple workers and calls the JSON API under the covers. For uploads it uses Composite Uploads when possible, and for downloads it uses range reads. It automatically parallelizes transfers by calculating an optimal chunk size and number of workers to transfer those chunks. You can also set a number of variables for uploads (parallel_composite_upload_*), downloads ( sliced_object_download_*), and workers (process_count and thread_count) as described in the gcloud config set documentation. I tried tweaking these settings to try and squeeze even more performance out but couldn’t improve on the default behavior.
Google Cloud Storage Python Libraries
The Google Cloud Storage libraries make it easier to work with GCS and are available for C++, C#, Go, Java, Node.js, PHP, Python, and Ruby. All of these can be used to upload files in parallel using the Compose pattern and your own multiprocessing logic. If you’re using Python or Node.js, these libraries also include a transfer_manager module that uses the XML Multipart API for uploads, and the JSON API for downloads, and handles the multiprocessing logic for you. Set the chunk_size and max_workers parameters and the module takes care of the rest.
Testing Time
Okay, enough theory, time for practice! I created a small script that uses the gcloud storage CLI and the transfer_manager module from the Google Cloud Storage Python client library to measure the throughput of the different transfer techniques. For these I used a c3-highmem-8 and a c3-standard-176 machine and copied data to and from a ramdisk to avoid disk bottlenecks and put the focus on the APIs and libraries. Especially at the higher throughput levels the disks (PD, Hyperdisk, Local SSD) will need to be sized appropriately. Lastly, some performance variation is normal. All results reported are the mean of 10 test runs where I discarded the best and worst values.
Serial Uploads
For these tests I used a 3 GiB file. To force gcloud to operate serially I set CLOUDSDK_STORAGE_PARALLEL_COMPOSITE_UPLOAD_ENABLED to False. Note: if your bucket is configured with retention, object holds, or uses a storage class other than STANDARD, gcloud storage will set this to False automatically to avoid interoperability issues with the chunk files. For Python I used the upload_from_filename method.
Here are the results:
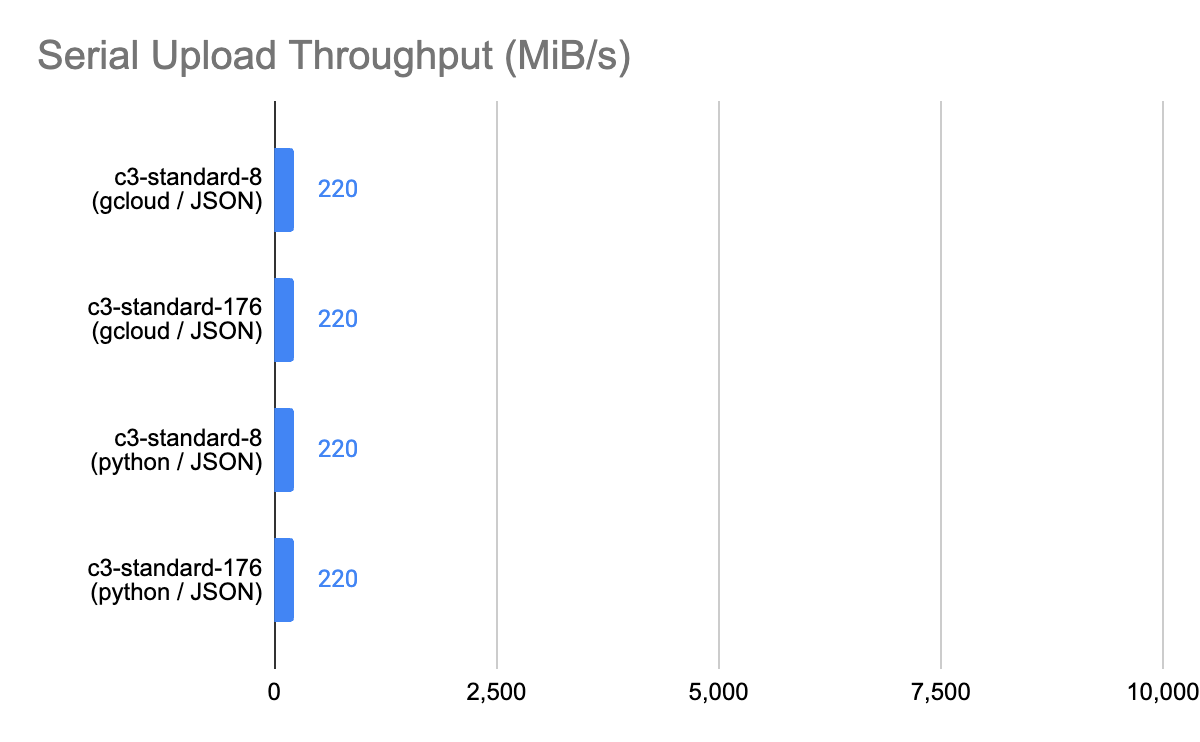 |
Observations: Appears to be typical single stream throughput delivered by GCS. Adding more vCPU, or using a different copy utility has no impact. |
Serial Downloads
For these tests I used a 3 GiB file. To force gcloud to operate serially I set CLOUDSDK_STORAGE_SLICED_OBJECT_DOWNLOAD_THRESHOLD to 0. For Python I used the download_to_filename method.
Here are the results:
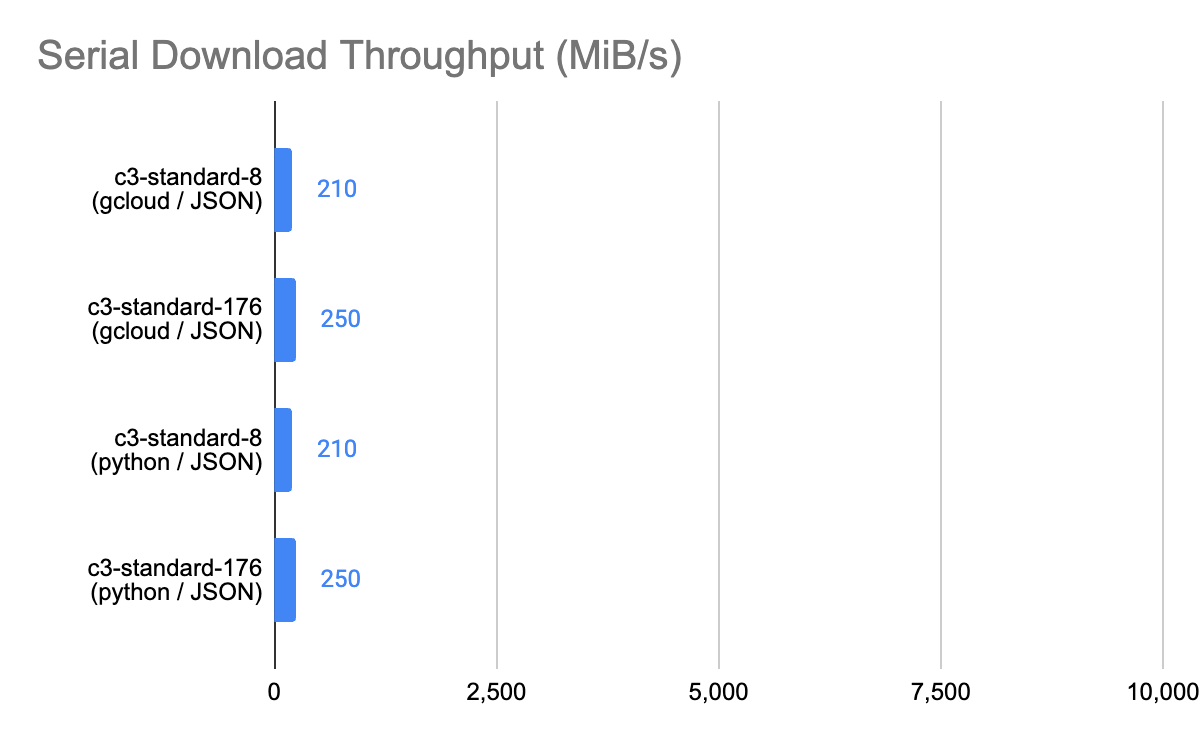 |
Observations: Appears to be typical single stream throughput delivered by GCS. Adding more vCPU, or using a different copy utility has no impact. |
Parallel Uploads
For these tests I used either a 40 GiB (8 vCPU VM) or 80 GiB (176 vCPU VM) file. For gcloud I allowed it to optimize the parallelization settings, and for Python I used the upload_chunks_concurrently method with a 25 MiB chunk size and either 50 (c3-highmem-8) or 176 (c3-standard-176) workers.
Here are the results:
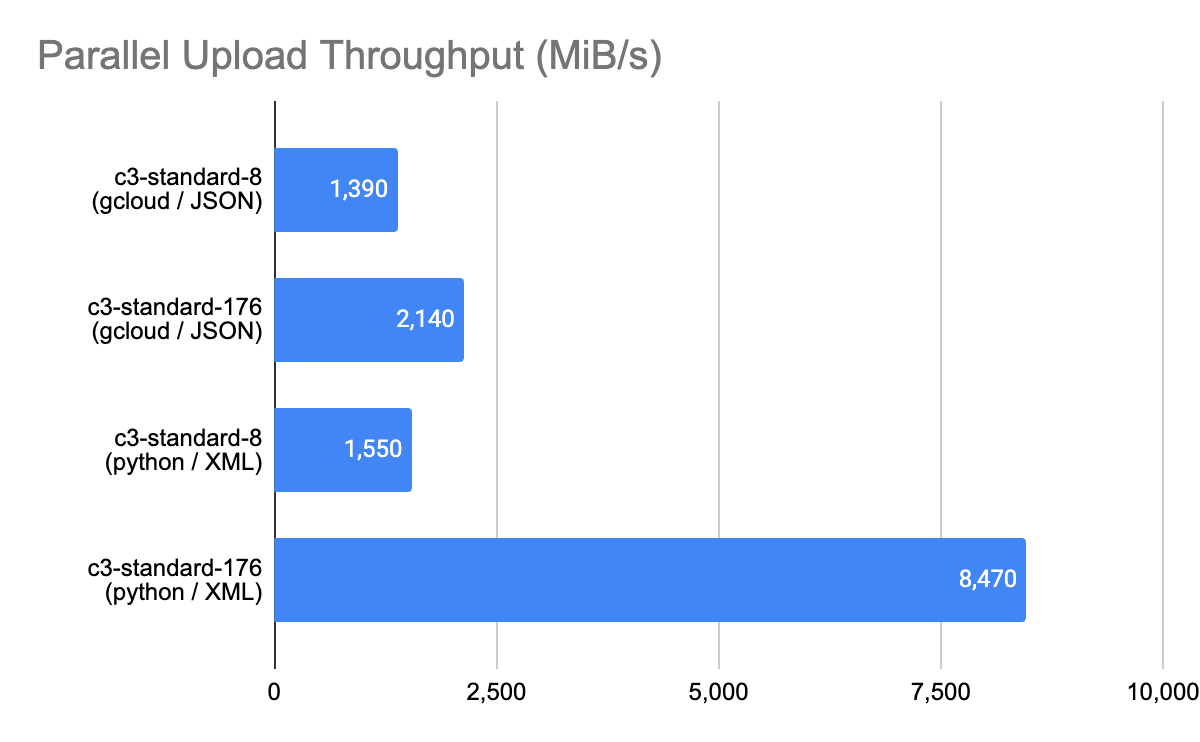 |
Observations: Here we see the benefit of increased parallelism possible with the Multipart XML API found in the transfer_manager module of the GCS Python libraries. On the 8 vCPU VM the difference is marginal because the 32 parallel streams possible with the Compose pattern uses most of the VM resources, but on the larger shape we can drive much higher throughput with greater parallelism. |
Parallel Downloads
For these tests I used either a 40 GiB (8 vCPU VM) or 80 GiB (176 vCPU VM) file. When using gcloud storage I allowed it to optimize the parallelization settings, and for Python I used the download_chunks_concurrently method with a 25 MiB chunk size and either 50 (c3-highmem-8) or 176 (c3-standard-176) workers.
Here are the results:
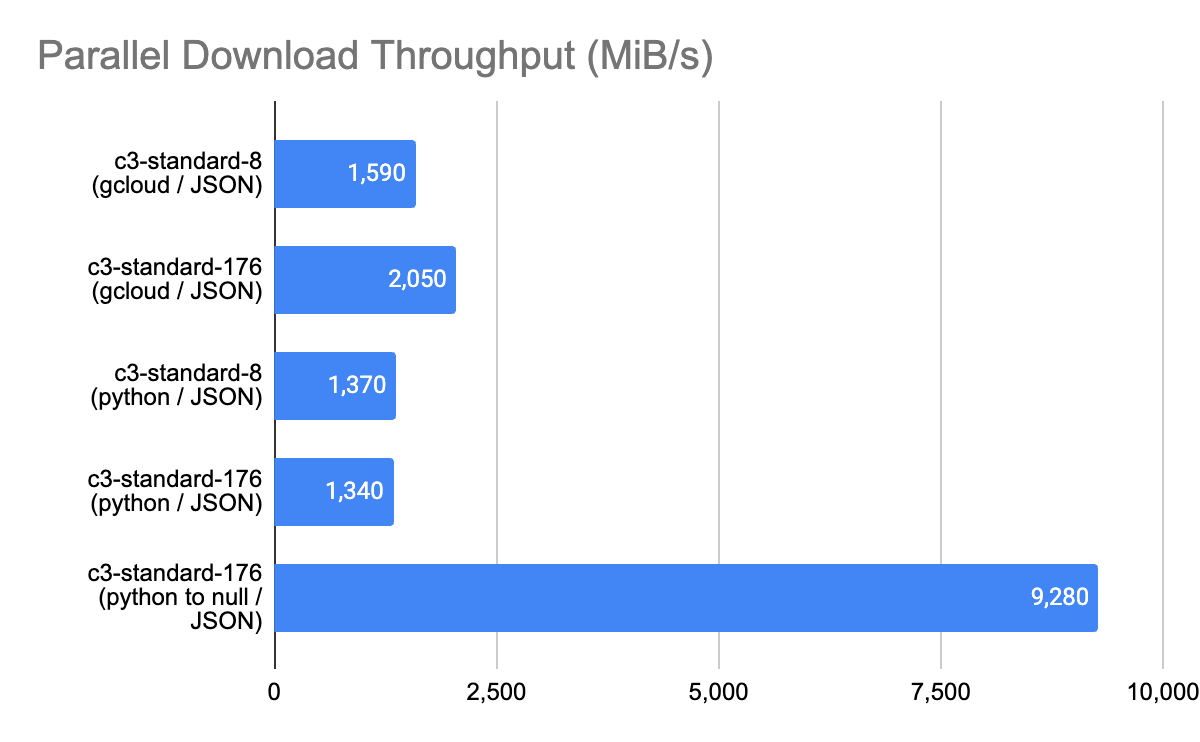 |
Observations:gcloud storage consistently delivered greater throughput than the transfer_manager module when saving to a file on the ramdisk. However when saving to /dev/null to approximate a direct load to application memory, we can achieve a much higher throughput level. I suspect the throughput when saving to a file is gated by file or filesystem concurrency inherent in the Python implementation found in these two tools. |
Recommendations
GCS is highly performant and delivers over 200 MiB/s streaming per transfer request for uploads or downloads. Greater throughput requires parallelization and the VM vCPU count, network limit, and storage limits will become your gating factors. For uploads, the Multipart Upload XML API delivers the highest throughput with the lowest implementation effort, and provides the best compatibility with GCS features. For downloads, the XML and JSON APIs with range reads are basically equivalent.
As always, comments are welcome!