If you’ve ever had to move a Google Cloud Storage bucket from one storage location to another you know it’s not easy or cheap. Maybe you needed to move it to a different region to be closer to your compute instances for better performance, or perhaps to reduce cost. In the past, this meant a manual, multi-step process of creating a new bucket, transferring the data, and then updating all your applications to point to the new bucket. Retaining the same bucket name required an additional copy process back to the original bucket name. All this was time-consuming, error prone, and required a fair amount of downtime.
Fortunately, GCS recently released the Bucket Relocation feature that makes it much easier. In this post, you’ll learn the what, why, and how of this feature adding a new tool to your data management toolbelt.
What is GCS Bucket Relocation?
Bucket Relocation, a feature of the Storage Intelligence product, allows you to change the storage location of an existing bucket from one location to another with no downtime for reads, and limited or no downtime for writes.
Some key points:
- Easy to use: No complex scripting or manual data transfers, as little as ONE command!
- Minimal Downtime: Your applications can continue to read from the bucket during all phases of relocation. In the finalize phase writes are allowed or blocked depending on the location specifics of the move.
- Metadata Preservation: All object metadata, such as creation time, storage class, and custom metadata, are preserved during the move.
- Friendly with Colder Storage Classes: There are no retrieval fees for data stored at colder classes and Autoclass data is not promoted to Standard on transfer.
- No Application Changes: Since the bucket name doesn’t change no client updates are needed.
Although there is one bucket relocation feature, under the covers there are two scenarios that come with different limitations:
| Without write downtime | With write downtime | |
| Storage Locations | Moves within the same continent (e.g. us, eu) between configurable dual region locations and/or a multi-region location. For example a configurable dual region us-east1/us-central1 to US multi-region. | All other moves, for example across continents or when using regional or predefined dual-regions buckets. For example a regional bucket move from us-east1 to us-central1 |
| Finalize Stage | No finalize stage required. After started the job will move data and manage the cutover completing after a 7-day period to ensure write consistency. | Yes, a finalize is required. During the finalize the bucket is read-only and all modifications such as writes or deletes will be blocked. |
| Limitations | A small, but important list of limitations | A longer, important and quite nuanced list of limitations |
When to use bucket relocation?
This is not a feature you set out to use on day one, but rather a feature that comes in extremely handy to respond to changes such as:
- Improve Performance: Co-locate storage and compute to reduce access latency and increase throughput.
- Reduce Cost: Co-locate storage with compute to reduce network charges. Move data archives to regions with lower pricing.
- Change Resilience: Move from regional to dual-regional, or multi-regional to regional, as your needs change.
How does bucket relocation work?
While the concept is simple - move a bucket from A to B - there are several stages to make it happen:
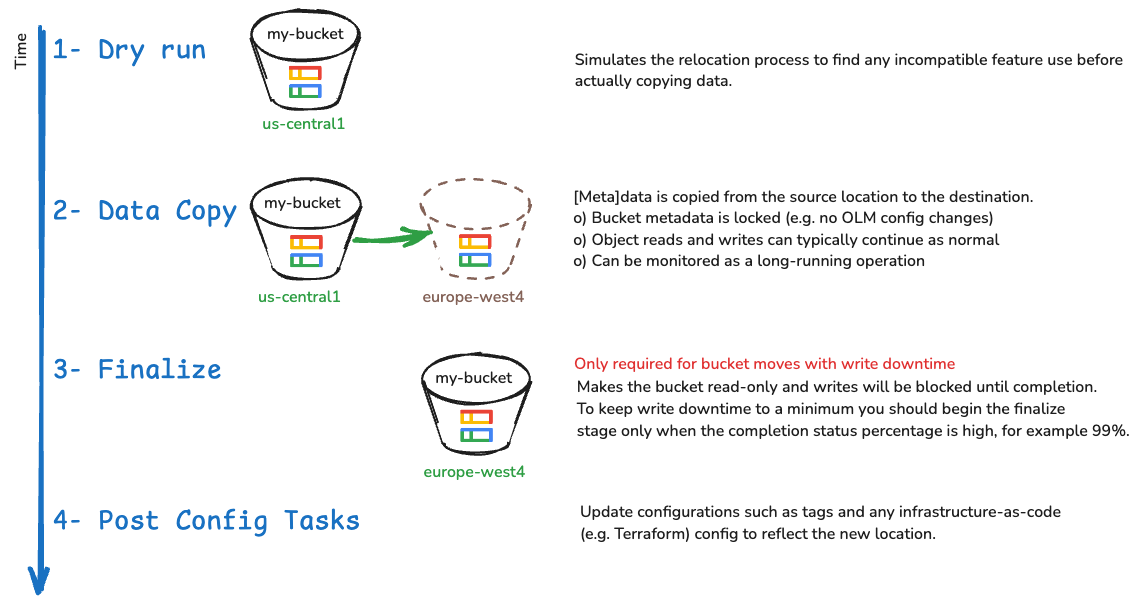
You can use the CLI/API or Cloud Console to manage bucket relocation. Below you will find two sections with steps for the CLI and Cloud Console respectively.
Turning Theory into Practice (CLI)
I ran a bucket relocate job on a regional bucket (100k objects, 155 GiB) moving it from europe-west4 to europe-west1. Here are the steps and my experience:
(1) Verify Prerequisites:
Before you can relocate a bucket you must comply with the following three points:
- Storage Intelligence: The bucket relocation feature is part of Storage Intelligence, so you’ll need to have it enabled. You can enable at the project, folder, or org levels, using the 30-day trial if you like.
- IAM Roles: You’ll need the Storage Admin (roles/storage.admin) IAM role on the project.
- Soft Delete: Your bucket must have soft delete enabled with at least 7 days of retention.
(2) Dry Run:
I started a job with the --dry-run flag and checked the job for success.
gcloud storage buckets relocate gs://bucket-on-the-move --location=europe-west1 --dry-run
gcloud storage operations list projects/_/buckets/bucket-on-the-move
(3) Initial Data Copy
Now I ran the exact same command but omitting the --dry-run flag. The command returns the operation ID that you can use to monitor.
gcloud storage buckets relocate gs://bucket-on-the-move --location=europe-west1
WARNING: The bucket gs://bucket-on-the-move is in EUROPE-WEST4.
WARNING:
1. This move will involve write downtime.
2. In-flight resumable uploads not finished before the write downtime will be lost.
3. Bucket tags added to the bucket will result in the relocation being canceled.
4. Please ensure that you have sufficient quota in the destination before performing the relocation.
Please acknowledge that you've read the above warnings and want to relocate the bucket gs://bucket-on-the-move? (Y/n)?
...
selfLink: https://www.googleapis.com/storage/v1/b/bucket-on-the-move/operations/CiQxOTI1OWYyOS00ZjBmLTRjNzEtYjAzMC0wMjZlMGI5ZWI1MDUQBQ
(4) Monitor Job
Job statistics are available via the API or gcloud but are not shown in an easy to read format and there is no watch command. Also, they seem to be slow moving with infrequent updates; tens of minutes with no updated statistics was not unusual. I wrote a small shell script to allow me to monitor the job, get it from my Github repo here.
The output (from the whole job, start to finish, with largely redundant lines removed) was:
./monitor-bucket-relocate.sh bucket-on-the-move CiQxOTI1OWYyOS00ZjBmLTRjNzEtYjAzMC0wMjZlMGI5ZWI1MDUQBQ
Monitoring GCS operation: projects/_/buckets/bucket-on-the-move/operations/CiQxOTI1OWYyOS00ZjBmLTRjNzEtYjAzMC0wMjZlMGI5ZWI1MDUQBQ
Polling every 5 seconds and output only on changes
________________________________________________________________________________________________________________________
Timestamp (Elapsed) |Status |Job |Objects |Capacity GiB
| |% |% (done/total) |% (done/total)
2025-10-10 10:31:22 UTC (00:03:04) |WAITING_ON_SYNC (SYNCING)|0% |0% (0/0) |0% (0.00/0.00)
2025-10-10 10:47:08 UTC (00:18:08) |READY (SYNCING) |0% |0% (0/100000) |0% (0.00/155.83)
2025-10-10 10:57:12 UTC (00:28:12) |READY (SYNCING) |41% |41% (41000/100000) |41% (63.89/155.83)
2025-10-10 11:02:10 UTC (00:34:50) |READY (SYNCING) |99% |100% (100000/100000) |100% (155.83/155.83)
2025-10-10 11:03:25 UTC (00:36:06) |RUNNING (FINALIZING) |99% |100% (100000/100000) |100% (155.83/155.83)
2025-10-10 11:59:23 UTC (01:31:59) |FINALIZED (SUCCEEDED) |100% |100% (100000/100000) |100% (155.83/155.83)
________________________________________________________________________________________________________________________
Operation completed successfully.
To view the raw output of this operation, run:
gcloud storage operations describe projects/_/buckets/bucket-on-the-move/operations/CiQxOTI1OWYyOS00ZjBmLTRjNzEtYjAzMC0wMjZlMGI5ZWI1MDUQBQ
(5) Final Synchronization
Once I saw the Job status had reached 99% in the above output (after 36 minutes) I initiated the finalize:
gcloud storage buckets relocate --operation=projects/_/buckets/bucket-on-the-move/operations/CiQxOTI1OWYyOS00ZjBmLTRjNzEtYjAzMC0wMjZlMGI5ZWI1MDUQBQ --finalize
WARNING:
1. Any ongoing, in-flight resumable uploads will be canceled and lost.
2. Write downtime will be incurred.
This will start the write downtime for your relocation of gs://bucket-on-the-move, are you sure you want to
continue? (Y/n)? Y
Sent request to advance relocation for bucket gs://bucket-on-the-move with operation CiQxOTI1OWYyOS00ZjBmLTRjNzEtYjAzMC0wMjZlMGI5ZWI1MDUQBQ.
I then tried to write an object to the bucket and observed the write lock blocked it as expected:
gcloud storage cp file.data gs://bucket-on-the-move/updates/file.data.new
Copying file://file.data to gs://bucket-on-the-move/updates/file.data.new
ERROR: HTTPError 412: This bucket is being relocated and is in the finalization step. Object writes are blocked during this state.
As expected, reads are still allowed:
gcloud storage cp gs://bucket-on-the-move/updates/file.data file.data
Copying gs://bucket-on-the-move/updates/file.data to file://file.data
Completed files 1/1 | 83.8kiB/83.8kiB
(6) Validation and Post Relocation Tasks
After an hour or so I saw my monitor script completed reporting a successful bucket move. I checked the bucket location saw it was updated, and then copied a file to verify the object write lock had been removed:
gcloud storage buckets describe gs://bucket-on-the-move | grep location:
location: EUROPE-WEST1
gcloud storage cp file.data gs://bucket-on-the-move/updates/file.data.new
Copying file://file.data to gs://bucket-on-the-move/updates/file.data.new
Completed files 1/1 | 83.8kiB/83.8kiB
I wasn’t using object tags or inventory reports, and don’t have an IaaC like Terraform to update a bucket location, so all tasks are done. 🎉
Turning Theory into Practice (Cloud Console)
You can also relocate a bucket from the Cloud Console. I ran a bucket relocate job on a regional bucket (2 objects, 33 MiB) moving it from europe-west4 to europe-west1.
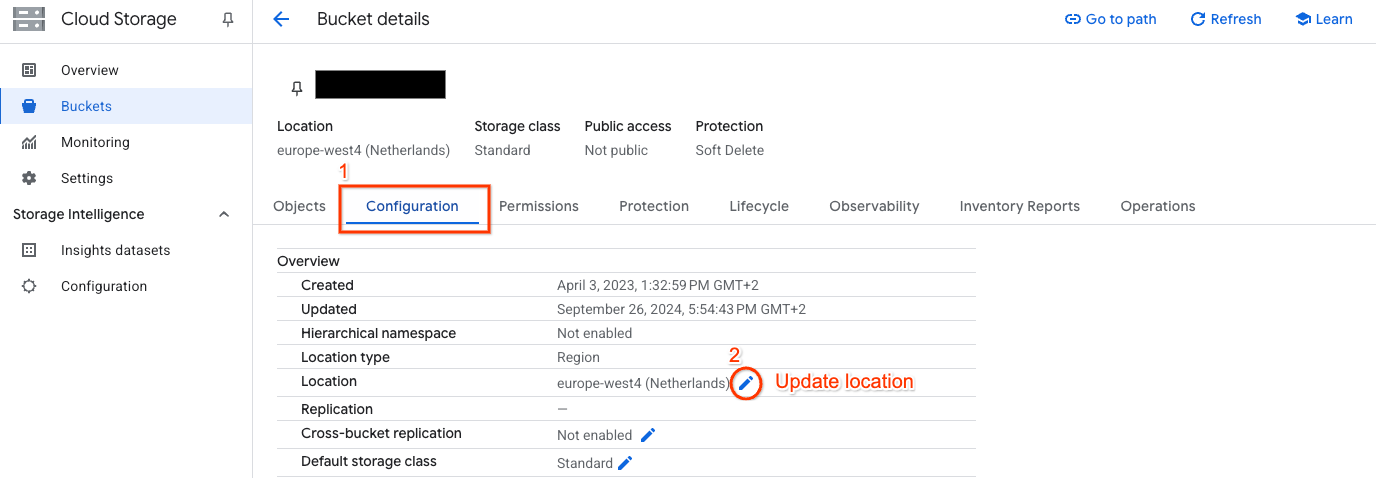
Click on a bucket, and then the Configuration tab and you will see a Edit pencil icon next to the bucket location:
Choose the desired destination location and start a dry-run:
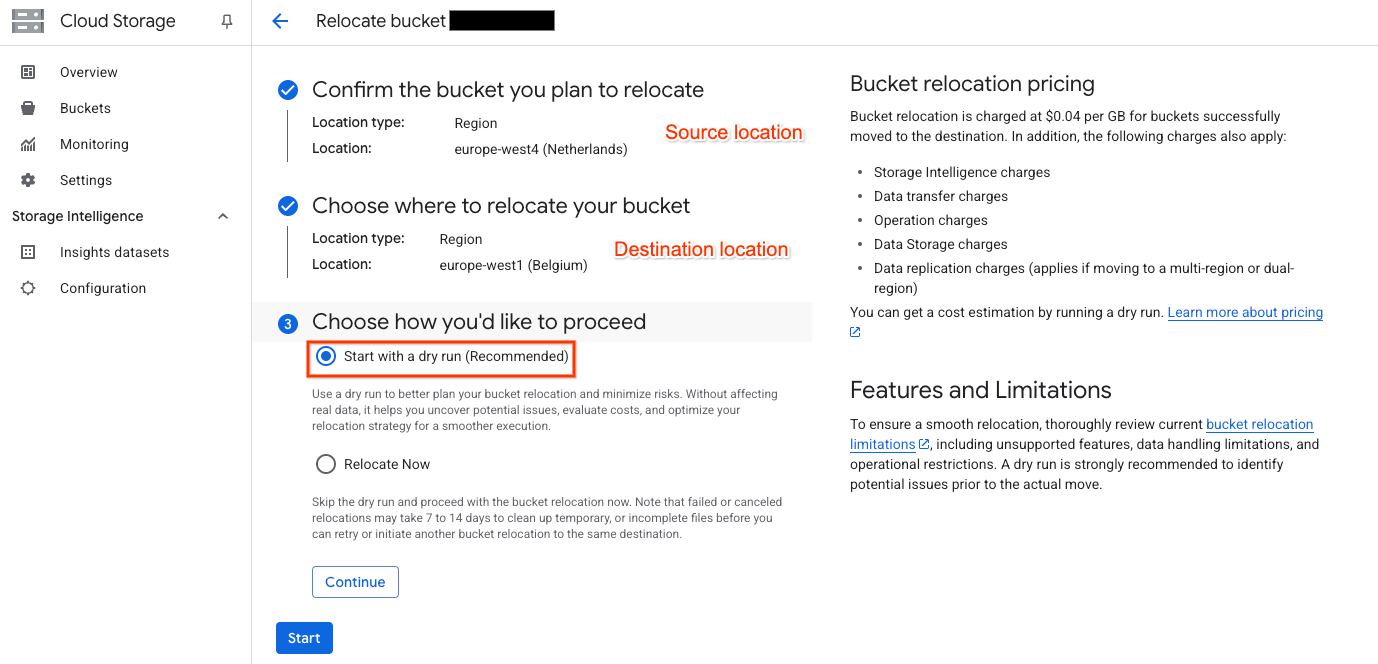
Review the results, in this case there were several files which had been uploaded via XML Multipart Uploads (MPU) which are not supported. Details of the object names are in Cloud Logging:
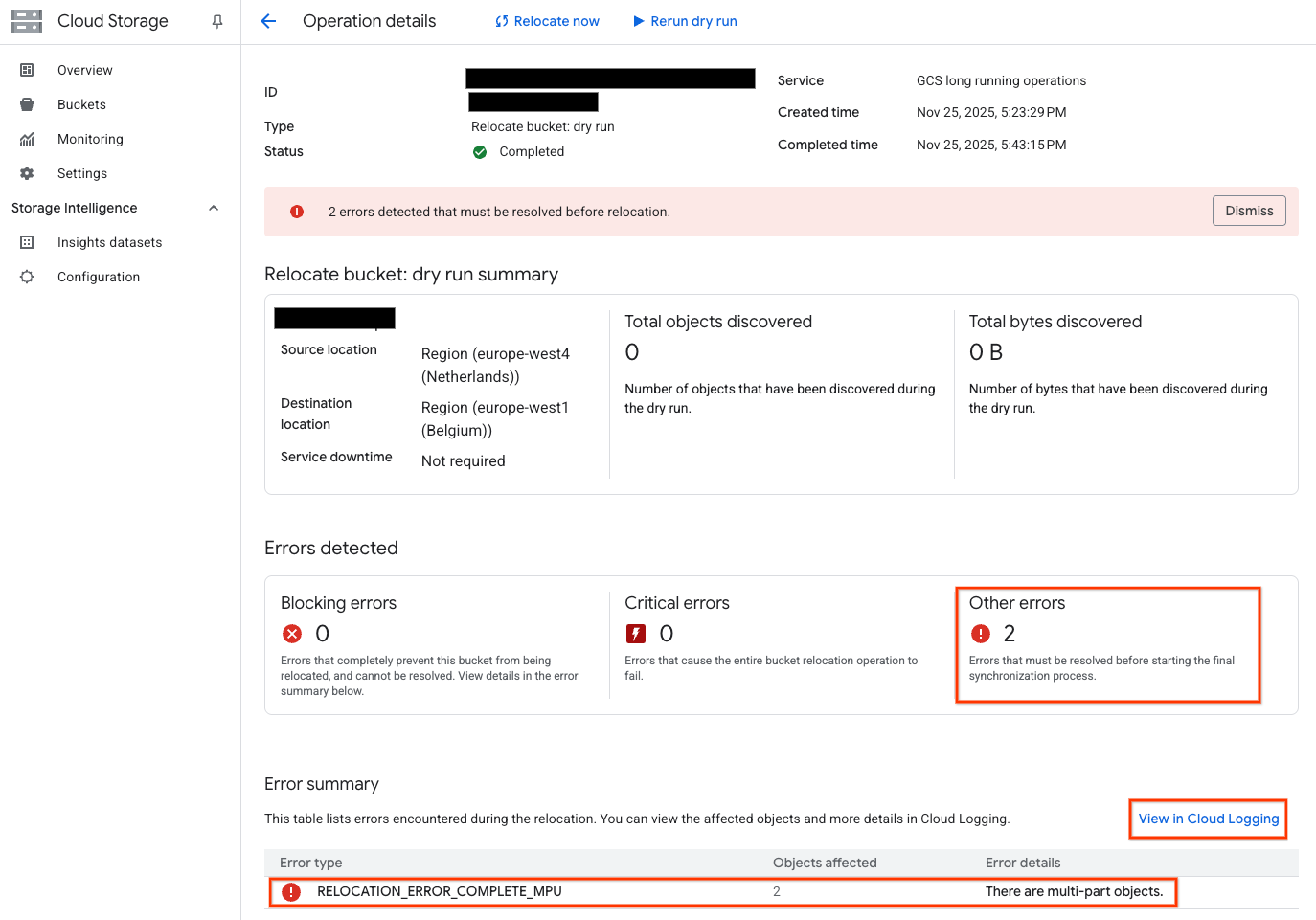
Fix any issues, and then start the actual data sync using the Relocate now button.
During the initial sync the bucket remains in read/write mode:
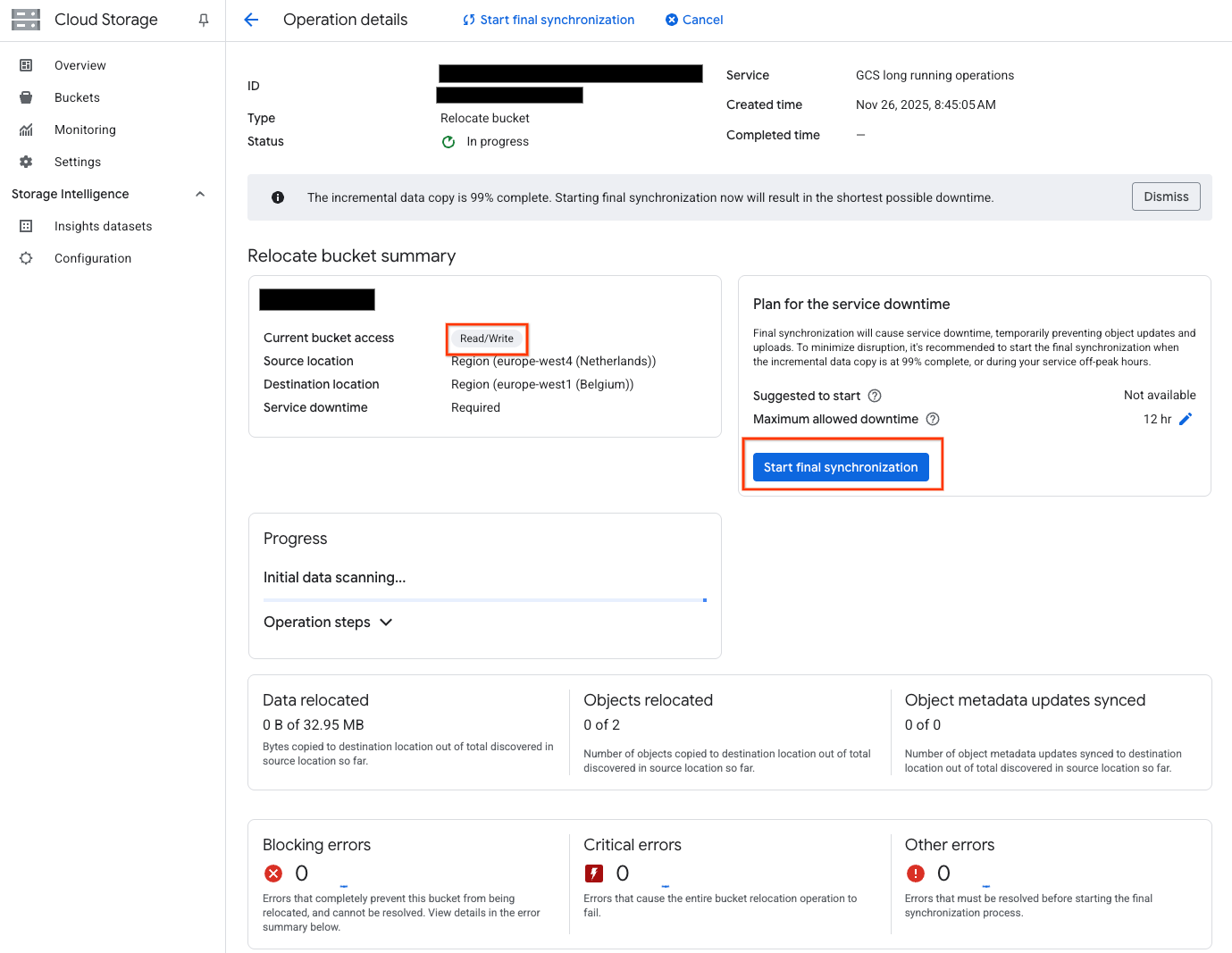
When the sync is 99% complete, click the Start final synchronization button to start the cutover. For a region to region move the bucket will become read-only:
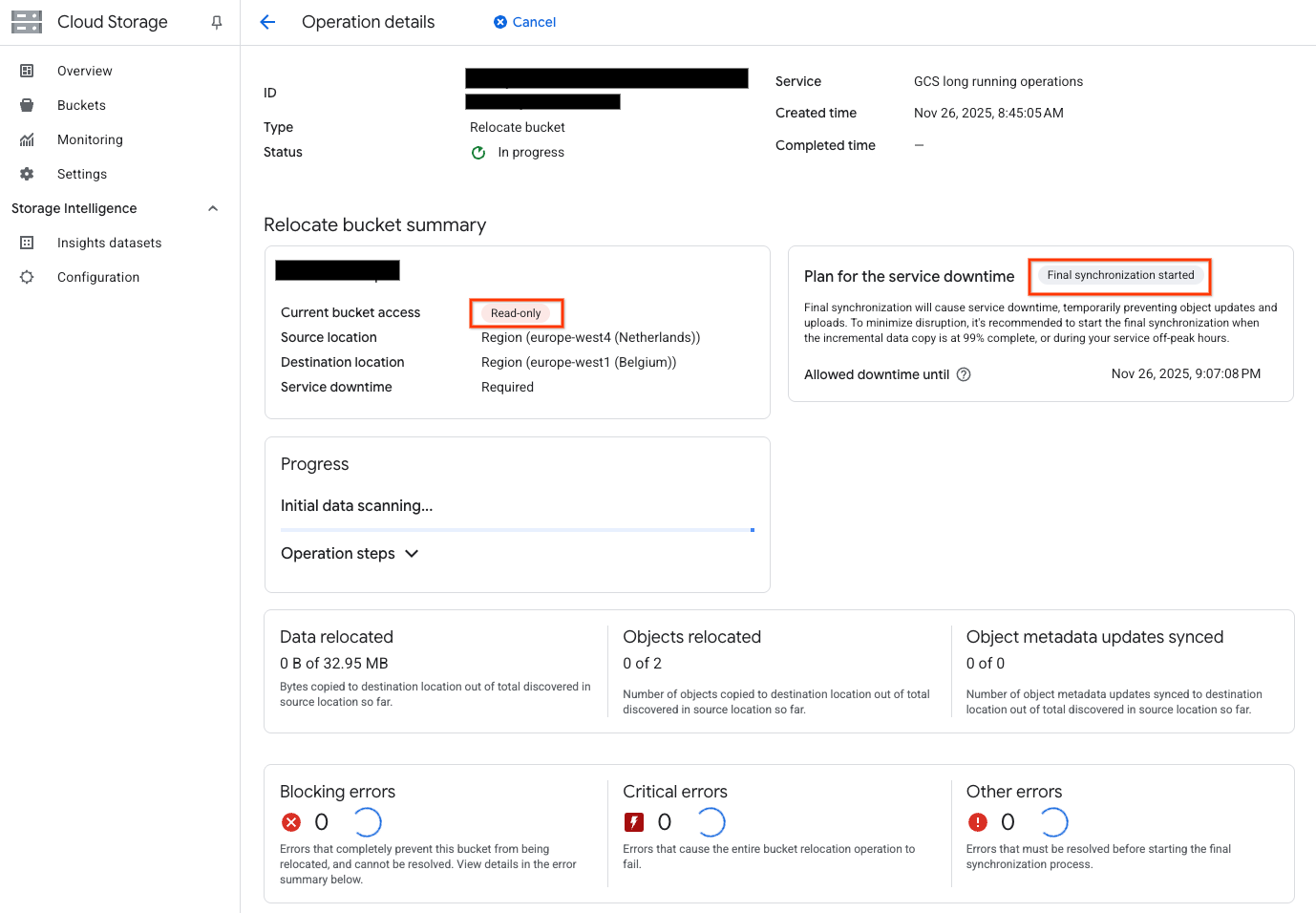
After some time, the sync will complete and the bucket will automatically become read/write again in the new storage location:

Gotchas and Things to Consider
While experimenting here are a few things I discovered to keep in mind:
Limitations: Read the limitations (Without write downtime or With write downtime) that are applicable to your scenario. Don’t skim them, read them thoroughly. The use of XML Multipart uploads (temporarily or ever depending on scenario), HNS buckets, having locked objects, etc, can all prevent the use of this feature. The limitations are nuanced and rather than repeating here please read the docs directly. The
--dry-runis a safeguard to run before the move if you expect your bucket is supported for a move.Cost: You incur a relocation fee which includes a transfer charge of $0.04 per GiB of data moved, plus Class A operations charges for the relocation operation (billed per object moved), and potentially data transfer network fees and GCS inter-region replication fees if moving to a dual-region or multi-region. Your bucket must also be enrolled in Storage Intelligence, but there is a 30 day free trial removing any cost if you unenroll after the bucket relocate completes.
Anywhere Cache: If your data is in a multi-region bucket and you want to reduce network costs, considering adding an Anywhere Cache to the compute zones that access it. For some workloads this will save you the network costs AND increase performance and you can leave the bucket where it is!
Conclusion
The bucket relocation feature allows you to move buckets with relative ease to optimize cost, improve performance, or achieve resilience goals. Use the knowledge gained in this post to give it a try in your environment!